
Why 'brownfield' codebases break coding agents, and how 'intentional compaction' restores their intelligence.
Summary
While AI coding agents excel at generating greenfield prototypes, they frequently falter in complex, existing ('brownfield') codebases, producing what engineers term 'slop'—code that requires significant rework. This failure is often not a lack of model intelligence, but a mismanagement of the context window. As context fills, Large Language Models (LLMs) suffer from performance degradation, particularly in the 'dumb zone' where reasoning capabilities decline.
This article introduces Context Engineering, a methodology that treats the context window as a scarce, engineered resource. By replacing chat-based loops with a rigorous Research, Plan, Implement (RPI) workflow, developers can use 'intentional compaction' to maintain high model performance. We explore the physics of context decay, the fallacy of 'spec-driven development,' and how shifting human effort from code review to plan review creates the mental alignment necessary for high-velocity AI engineering.
Key Takeaways; TLDR;
- The Brownfield Paradox: AI agents thrive on new projects but degrade in legacy codebases due to context overload and complexity.
- The 'Dumb Zone': LLM performance is not uniform; reasoning quality drops significantly (the 'Lost in the Middle' phenomenon) as the context window fills past ~40%.
- Intentional Compaction: To maintain intelligence, engineers must compress context between steps, summarizing findings into a 'truth snapshot' rather than retaining full conversation history.
- RPI Workflow: A structured cycle of Research (gathering facts), Plan (compressing intent), and Implement (executing with clean context) prevents 'slop.'
- Mental Alignment: The primary role of the senior engineer shifts from reviewing lines of code to reviewing the plan, where a single correction prevents hundreds of lines of bad code.
- Semantic Diffusion: Terms like 'spec-driven dev' have lost meaning; the focus must remain on the mechanics of context management rather than buzzwords.
The Brownfield Paradox
There is a widening chasm in the adoption of AI software engineering tools. On one side, junior developers and founders building 'greenfield' prototypes—fresh dashboards, simple scripts, isolated apps—report miraculous productivity gains. On the other, staff engineers working in ten-year-old Java or Rust monorepos often find the same tools counterproductive. They report a phenomenon increasingly known as "slop": AI-generated code that looks plausible but introduces subtle bugs, violates architectural patterns, or requires so much rework that doing it manually would have been faster.
Recent data supports this skepticism. A 2024 analysis of over 150 million lines of code found that while coding speed has increased, code churn—the percentage of code reverted or rewritten within two weeks—has nearly doubled compared to pre-AI baselines . We are shipping more code, but we are also throwing more of it away.
The culprit is rarely the model's raw intelligence. It is a failure of context. In a pristine greenfield project, the entire codebase fits in the model's working memory. In a "brownfield" system—laden with legacy dependencies, undocumented hacks, and sprawling file structures—the model is forced to operate with partial, noisy, or hallucinated information. To bridge this gap, we need a shift from prompt engineering to Context Engineering: the rigorous architectural discipline of managing what enters the model's limited cognitive horizon.
The Physics of the Context Window
Large Language Models (LLMs) are stateless functions. They have no memory of previous interactions other than what is passed in the current prompt. While context windows have grown from 4k to 100k+ tokens, treating this space as an infinite bucket is a fundamental error.
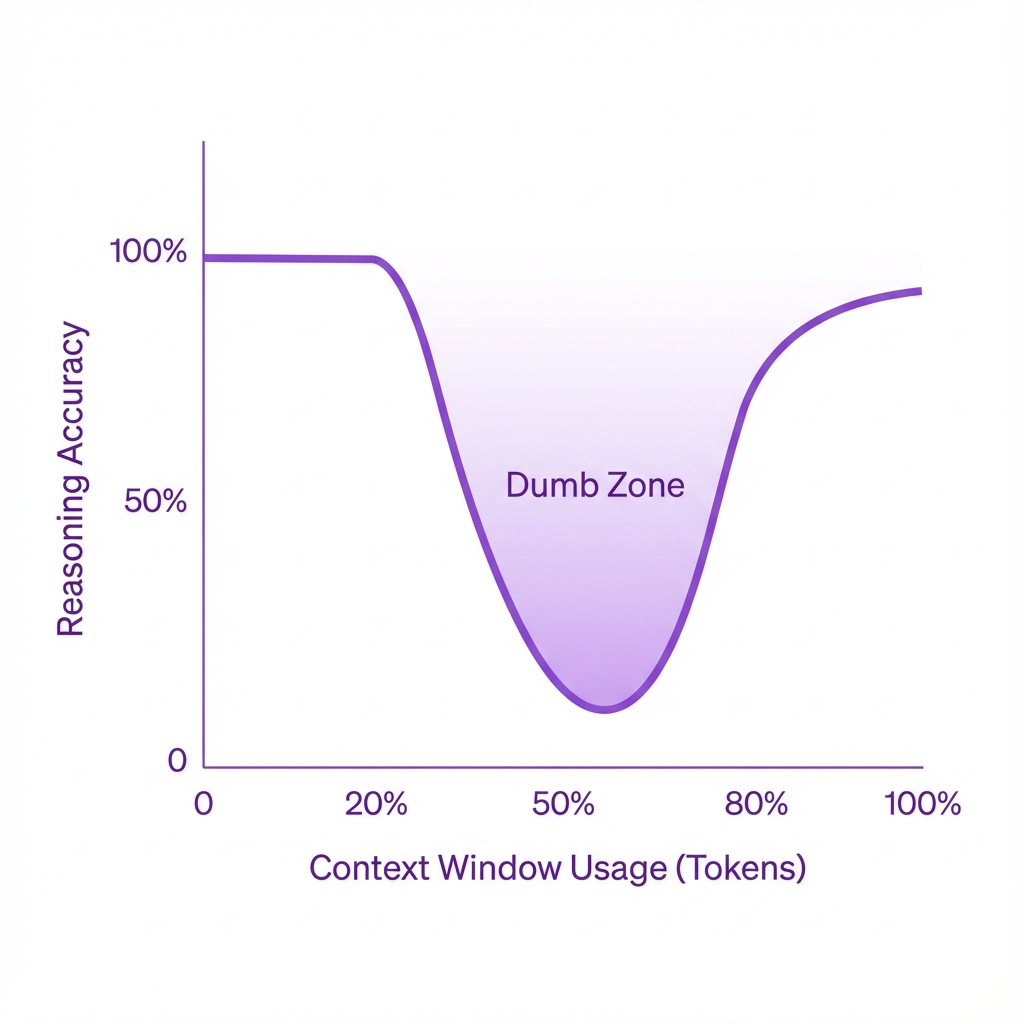
The Dumb Zone: As the context window fills, the model's ability to retrieve information and reason correctly degrades, particularly in the middle of the sequence.
Research into LLM performance reveals a non-linear relationship between context length and reasoning ability. This is often described as the "Lost in the Middle" phenomenon . When relevant information is buried in the middle of a long context window, retrieval accuracy and reasoning capability degrade significantly.
We can conceptualize this as the "Dumb Zone." As a conversation with a coding agent drags on—accumulating file dumps, error logs, and failed attempts—the context window fills with noise. Once the window passes a certain saturation point (often around 40-50% of capacity, depending on the model), the agent's ability to follow complex instructions or adhere to strict architectural patterns collapses. The agent isn't just running out of space; it is running out of focus.
Escaping the 'Dumb Zone'
The naive approach to fixing a struggling agent is to "yell" at it—providing more instructions, more error logs, and more corrections. This creates a negative feedback loop. The model sees a history of failure and correction, which, due to the probabilistic nature of token generation, can actually increase the likelihood of further errors.
Context Engineering solves this by enforcing Intentional Compaction. Instead of a continuous, degrading chat stream, the workflow is broken into discrete stages. Between each stage, the context is aggressively compressed, discarding the noise of the process and retaining only the "truth" required for the next step.
Methodology: Research, Plan, Implement (RPI)
To operationalize context engineering, we move away from open-ended chat and toward a structured workflow: Research, Plan, Implement (RPI). This structure is designed to keep the agent in the "Smart Zone" (the high-performance early segment of the context window) for every distinct task.
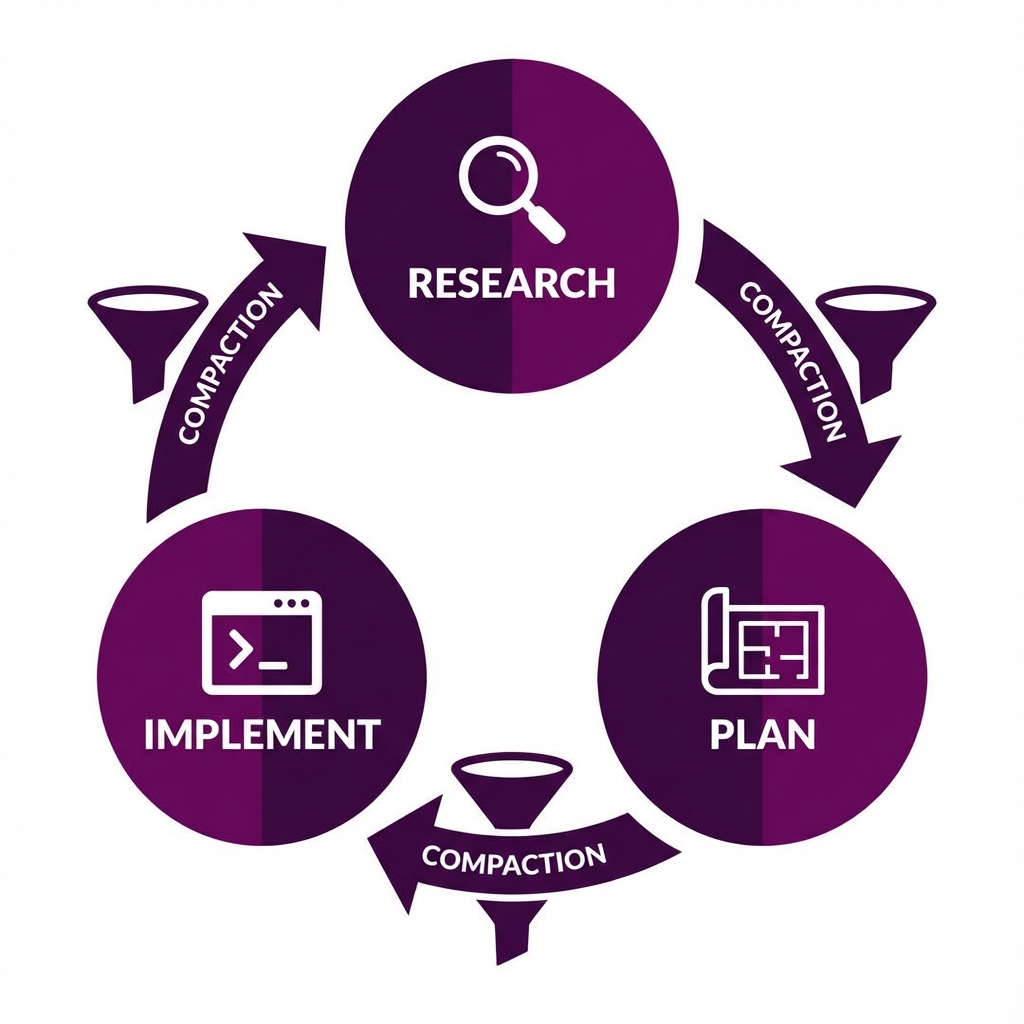
The RPI Cycle: By compacting context between phases, we ensure the agent starts the critical Implementation phase with a clean, high-signal context window.
Phase 1: Research (Dynamic Context Discovery)
In a large codebase, you cannot simply "feed the files" to the model. The context window is too small, and the noise ratio is too high. The goal of the Research phase is to create a map of the problem space.
The agent is tasked not with writing code, but with reading it. It explores the codebase, traces function calls, and identifies dependencies. Crucially, the output of this phase is not a conversation history, but a compressed artifact—a markdown file or summary that contains only the relevant file paths, snippets, and architectural constraints.
This differs from static documentation, which is almost always out of date (a measure of "lies per line of code"). This is on-demand compressed context: a fresh, verified snapshot of the system as it exists right now, tailored specifically to the task at hand.
Phase 2: Planning (Compression of Intent)
Planning is the highest-leverage activity in the AI engineering loop. A plan is effectively a compression of intent.
In this phase, the agent (or a fresh instance of the agent) takes the compressed research artifact and the user's request to generate a step-by-step execution plan. This plan should be granular, specifying:
- Exact files to modify.
- Pseudocode or actual snippets of the changes.
- Verification steps (tests) for each change.
This phase acts as a firewall against "slop." If the plan is vague or hallucinates a function that doesn't exist, the implementation will fail. By forcing the model to articulate the plan before writing code, we can catch these errors when they are cheap to fix.
Phase 3: Implementation (Clean Execution)
The Implementation phase begins with a clean context window. It does not need to know about the dead-ends explored during research or the back-and-forth of the planning negotiation. It only needs:
- The compressed Research artifact (the map).
- The approved Plan (the instructions).
Because the context is pristine and highly relevant, the model operates at peak performance. It is not distracted by previous errors or irrelevant file dumps. It simply executes the plan.
Mental Alignment: Redefining Code Review
The RPI workflow fundamentally changes the role of the human engineer. In traditional development, we review code after it is written. In AI-driven development, this is too late. If an agent generates 500 lines of code based on a flawed assumption, reviewing the diff is mentally exhausting and inefficient.
Context Engineering shifts the review process left, to the Plan phase.
"A bad line of code is a bad line of code. A bad line of a plan is a thousand bad lines of code."
Reviewing a plan allows the engineer to ensure Mental Alignment—verifying that the agent understands why a change is being made and how it fits into the broader system. It is far easier for a senior engineer to read a 50-line markdown plan and say, "No, don't use that deprecated API, use this service instead," than to untangle a spaghetti PR later.
This aligns with the concept of Semantic Diffusion, a term coined by Martin Fowler . As terms like "Agent" and "Spec-Driven Development" become buzzwords, they lose their precise meaning. We must be careful not to treat "planning" as a bureaucratic step or a rigid "waterfall" document. It is a dynamic, technical artifact designed to align the human's mental model with the AI's context window.
Conclusion: The New Engineering Discipline
The future of software engineering is not just about writing syntax; it is about managing the information flow between complex systems and non-deterministic models.
Tools that obscure this process—hiding the context management behind a simple "Chat" interface—often hit a ceiling of complexity. To break through that ceiling and tackle brownfield development, engineers must embrace Context Engineering. We must become architects of the prompt, curators of the context window, and rigorous reviewers of the plan. Only then can we move beyond generating "slop" and start building robust, maintainable systems at the speed of AI.
Why It Matters
As AI adoption matures, the divide between engineers who can wield these tools on legacy systems and those who can only use them for prototypes will grow. Mastering context compaction and the RPI workflow is the specific skill set that bridges that gap, turning the "dumb zone" of LLM limitations into a manageable constraint rather than a blocker.
I take on a small number of AI insights projects (think product or market research) each quarter. If you are working on something meaningful, lets talk. Subscribe or comment if this added value.
Appendices
Glossary
- Context Engineering: The practice of optimizing the information fed into an LLM's context window to maximize reasoning performance and minimize cost/latency.
- Brownfield Development: Software development performed on existing, legacy codebases, characterized by complexity, technical debt, and established patterns (as opposed to 'Greenfield' new projects).
- Intentional Compaction: The deliberate process of summarizing and compressing the state of an AI conversation or research phase into a concise artifact before proceeding to the next step.
- Slop: A colloquial term for low-quality, AI-generated code that is syntactically correct but functionally flawed, redundant, or unmaintainable.
Contrarian Views
- Some argue that massive context windows (1M+ tokens) will eventually render context engineering obsolete. However, current research suggests that reasoning capability still degrades with length, even if retrieval works.
- Critics of 'planning' phases argue it reintroduces Waterfall methodologies into Agile workflows. The counter-argument is that the plan is ephemeral and iterative, not a static requirements document.
Limitations
- The RPI method increases latency for simple tasks; it is overkill for one-line CSS changes.
- Requires a higher degree of developer discipline to review plans rather than just accepting code.
- Heavily dependent on the quality of the 'Research' phase; if the map is wrong, the plan will be wrong.
Further Reading
- Lost in the Middle: How Language Model Long Context Understanding is Tipping Point - https://arxiv.org/abs/2307.03172
- GitClear 2024 AI Code Quality Report - https://www.gitclear.com/research/ai_developer_productivity_review
- Benchmarking AI Agents (Qualz.ai) - https://qualz.ai
References
- Advanced Context Engineering for Agents - AI Engineer (video, 2024-08-25) https://www.youtube.com/watch?v=AnhXjOqX3j0 -> Primary source for the concepts of Context Engineering, RPI, and the 'Dumb Zone'.
- Coding on Copilot: 2024 Data Suggests Downward Pressure on Code Quality - GitClear (whitepaper, 2024-01-25) https://www.gitclear.com/research/ai_developer_productivity_review -> Provides statistical evidence for increased code churn and 'slop' in AI-assisted development.
- Lost in the Middle: How Language Model Long Context Understanding is Tipping Point - arXiv (Liu et al.) (journal, 2023-11-20) https://arxiv.org/abs/2307.03172 -> Academic validation of the performance degradation in the middle of long context windows.
- Semantic Diffusion - MartinFowler.com (org, 2006-12-14) https://martinfowler.com/bliki/SemanticDiffusion.html -> Defines the concept of terms losing meaning over time, applied here to 'Spec-Driven Dev'.
- Long Context RAG Performance of LLMs - Databricks (org, 2024-08-12) https://www.databricks.com/blog/long-context-rag-performance-llms -> Industry benchmarks confirming context saturation points.
- Software Engineering at Google - O'Reilly Media (book, 2020-03-01) https://abseil.io/resources/swe-book -> Foundational text on the complexity of 'brownfield' systems and Hyrum's Law.
- Retrieval Augmented Generation or Long-Context LLMs? - Google DeepMind / University of Michigan (journal, 2024-07-22) https://arxiv.org/abs/2407.16833 -> Compares long-context performance vs. retrieval, supporting the need for engineered context.
- Context Engineering for AI Agents - Kubiya (org, 2025-07-17) https://kubiya.ai/blog/context-engineering -> Industry perspective on the 12-factor agent framework and context engineering.
- Context Rot: How Increasing Input Tokens Impacts LLM Performance - Chroma Research (org, 2025-07-14) https://www.trychroma.com/blog/context-rot -> Detailed analysis of 'context rot' and the impact of distractors in the context window.
- Evaluating LLM Systems - Qualz.ai (org, 2024-01-01) https://qualz.ai -> Reference for benchmarking and evaluating the efficacy of AI agent outputs.
Recommended Resources
- Signal and Intent: A publication that decodes the timeless human intent behind today's technological signal.
- Thesis Strategies: Strategic research excellence — delivering consulting-grade qualitative synthesis for M&A and due diligence at AI speed.
- Blue Lens Research: AI-powered patient research platform for healthcare, ensuring compliance and deep, actionable insights.
- Lean Signal: Customer insights at startup speed — validating product-market fit with rapid, AI-powered qualitative research.
- Qualz.ai: Transforming qualitative research with an AI co-pilot designed to streamline data collection and analysis.