
Why 88% of AI pilots fail, and why the future belongs to system architects, not just model builders.
Summary
The initial wave of generative AI hype has crashed into a wall of engineering reality. While access to frontier models has been democratized, the success rate of enterprise AI projects remains alarmingly low, with recent data suggesting nearly 90% of pilots fail to reach production. This essay argues that the industry is undergoing a fundamental shift from a 'model-centric' view—obsessing over the latest benchmarks and pre-training statistics—to a 'system-centric' discipline defined as AI Engineering. Drawing on insights from AI researcher Chip Huyen and corroborating industry data, we explore why the true differentiation now lies in post-training techniques, rigorous data preparation for RAG, and the emerging paradigm of test-time compute. We dismantle the myth that better models solve all problems and posit that the future belongs to builders who master the unsexy, architectural glue that turns raw intelligence into reliable products.
Key Takeaways; TLDR;
- The 'Idea Crisis' is Real: Despite powerful tools, companies are stuck in 'pilot purgatory' (88% failure rate) because they lack clear use cases and rigorous engineering processes.
- Post-Training is the New Frontier: Differentiation has moved from pre-training base models to post-training techniques like SFT and RLHF that align models with specific user needs.
- RAG is a Data Problem: Success in Retrieval Augmented Generation depends on data hygiene and chunking strategies, not just choosing the trendy vector database of the week.
- Test-Time Compute: The industry is shifting toward 'thinking models' (inference-time scaling) that trade speed for accuracy via reasoning loops, rather than just making models larger.
- Evals Over Vibes: Moving from 'vibe checks' to systematic evaluations is the primary hurdle for scaling AI products from demo to production.
- The Rise of the AI Engineer: A new discipline is emerging that prioritizes system design, component orchestration, and user feedback over raw model building.
The Paradox of Abundance
We are currently living through a crisis of imagination disguised as a technology boom. The barriers to building with artificial intelligence have collapsed; what once required a PhD and a supercomputer now requires an API key and a credit card. Yet, despite this abundance of capability, the actual deployment of successful, value-generating AI products has stalled.
Industry data paints a stark picture of this "pilot purgatory." Recent reports indicate that approximately 88% of AI pilots never reach production . Even more concerning, the rate of abandoned projects has spiked significantly between 2024 and 2025. Companies are awash in tools—coding agents, design generators, automated copywriters—but they are starving for durable use cases.
The disconnect stems from a fundamental misunderstanding of where value is created in the generative AI stack. For the past two years, the collective gaze of the tech industry has been fixed on the model: Is GPT-5 coming? How does Claude 3.5 compare to Llama 3? This obsession with the "brain" of the operation ignores the body that must support it. The reality is that raw intelligence is becoming a commodity. The true engineering challenge—and the source of competitive advantage—has shifted downstream, into the messy, unglamorous work of system design, data preparation, and evaluation.
The Shift from Pre-Training to Post-Training
To understand why products fail, one must distinguish between the two phases of a model's life: pre-training and post-training.
Pre-training is the brute-force statistical modeling of language. It is the process of feeding a neural network the internet and teaching it to predict the next token. It is capital-intensive, data-hungry, and increasingly the domain of a few centralized "frontier labs." For 99% of engineers and companies, pre-training is a solved problem—you simply rent the result.
Post-training, however, is where the magic—and the differentiation—happens. This includes techniques like Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). If pre-training teaches a model to speak English, post-training teaches it to be a helpful customer support agent, a rigorous code reviewer, or a creative writer.
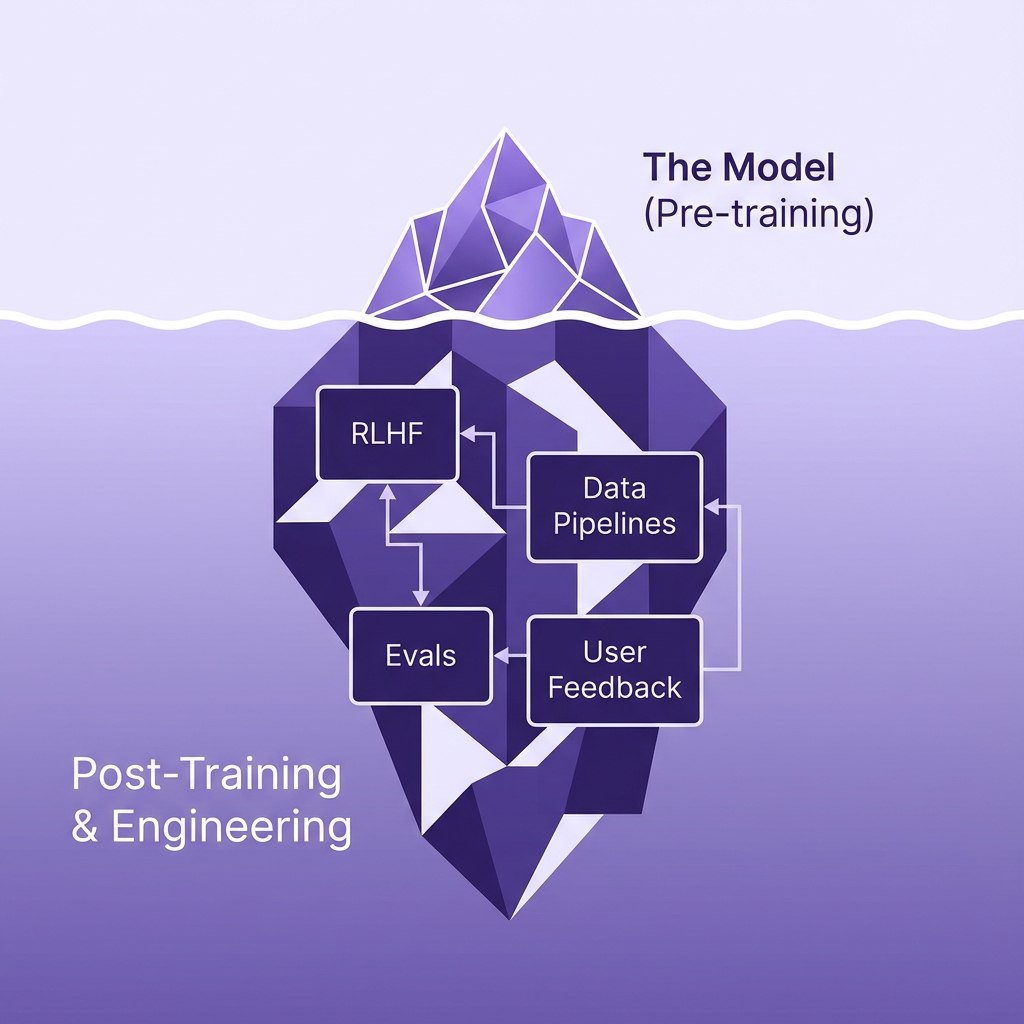
The AI Engineering Iceberg: While the industry obsesses over the base model (the tip), the reliability and value of an application are determined by the massive, unseen engineering work beneath the surface.
The industry's focus is rapidly pivoting to these post-training methods because they allow for domain specificity without the prohibitive cost of training from scratch. This is also where the economics of the AI supply chain become complex. The demand for high-quality, human-labeled data to feed these post-training loops has created a lopsided market. A vast array of data labeling startups are chasing a tiny number of frontier lab customers, leading to a precarious ecosystem .
For the application builder, the lesson is clear: stop waiting for a smarter base model to solve your product issues. The gains to be had from better prompting, fine-tuning, and system architecture often dwarf the marginal improvements between model generations.
RAG: The Unsexy Reality of Data Engineering
Nowhere is the gap between hype and engineering reality wider than in Retrieval Augmented Generation (RAG). The concept is simple: give the model a textbook so it doesn't have to hallucinate answers for the test.
In practice, however, engineers often fall into the "database trap." They agonize over which vector database to use—Pinecone, Weaviate, Milvus—treating the infrastructure as the solution. But a vector database is merely a container. The quality of a RAG system is almost entirely determined by the quality of the data before it enters the database.
Consider the problem of "chunking." If you slice a document into arbitrary 500-word segments, you sever the semantic connective tissue. A paragraph referring to "the CEO" might be separated from the paragraph that names her. When a user asks, "What did the CEO say?", the retrieval system fails because the relevant chunk lacks the keyword "CEO" or the specific name.
Sophisticated AI engineering involves complex data preparation strategies to solve this:
- Contextual Chunking: Including metadata or summaries with each chunk so it stands alone semantically.
- Hypothetical Questions: Using an LLM to generate questions that a specific chunk would answer, and indexing those questions instead of the raw text. This aligns the retrieval mechanism with the user's intent rather than just keyword matching.
- Hybrid Search: Combining vector (semantic) search with traditional keyword (lexical) search to catch specific terms that embeddings might miss.
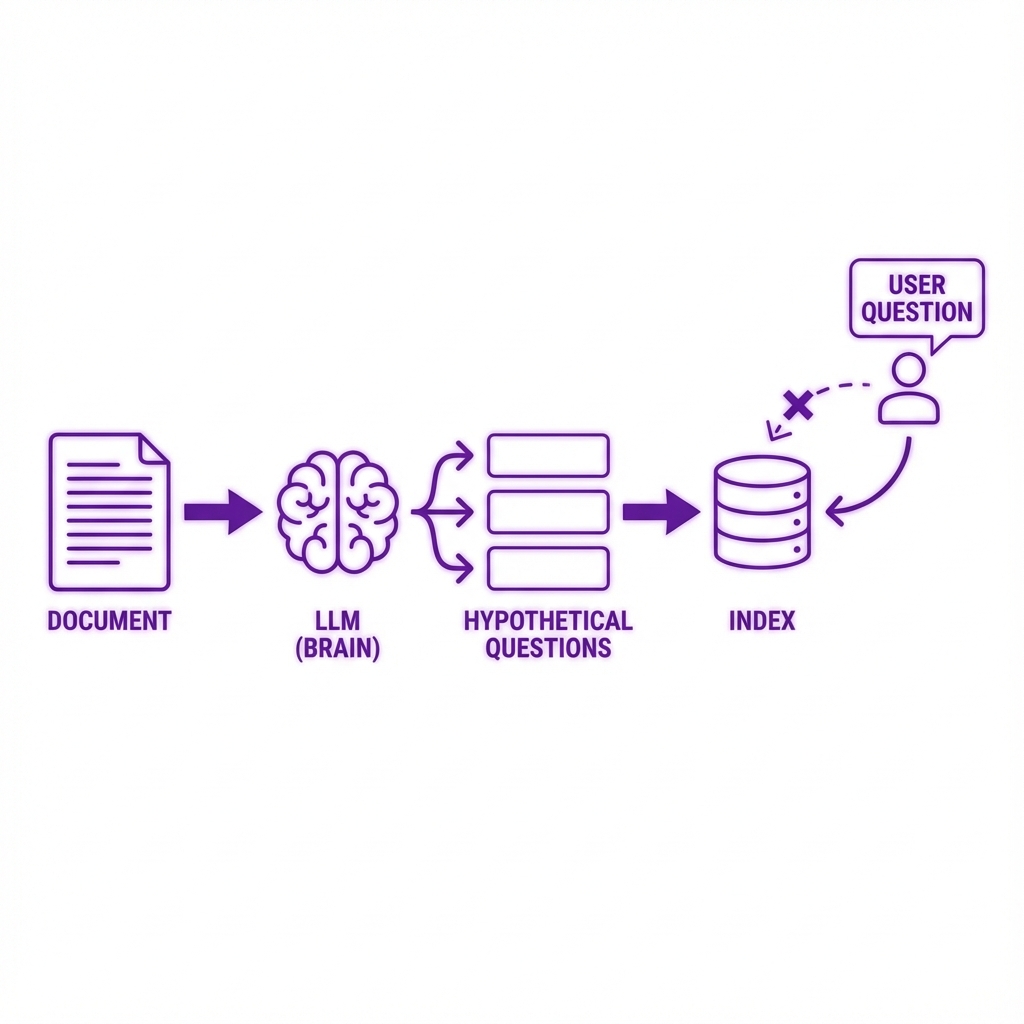
Optimizing Retrieval: Instead of indexing raw text, advanced RAG systems often index hypothetical questions that the text answers, aligning the database with user intent.
The most successful RAG implementations today are not defined by their tech stack, but by their data pipelines. They treat data preparation not as a one-time ETL job, but as an ongoing product feature.
The 'Thinking' Machine: A New Scaling Law
A major shift is occurring in how we utilize compute resources. For years, the scaling law was simple: bigger models (more parameters) equal better performance. We are now entering the era of Test-Time Compute.
This paradigm suggests that for complex reasoning tasks, we don't necessarily need a larger model; we need a model that "thinks" longer. This is evident in recent developments like OpenAI's o1 series, which utilize "chain of thought" processing at inference time . Instead of rushing to predict the next token immediately, the system generates internal reasoning steps, critiques its own logic, and backtracks if necessary before producing a final answer.
This has profound implications for AI engineering. It introduces a new trade-off: Latency vs. Intelligence.
- Fast Thinking: Standard inference. Good for chat, creative writing, and simple queries.
- Slow Thinking: High test-time compute. Essential for coding, math, and complex strategic planning.
Engineers must now design systems that can dynamically toggle between these modes. A coding assistant, for example, might use a fast, cheap model for autocomplete but switch to a slow, reasoning-heavy model for debugging a complex system error. This is "System Thinking" in action—architecting a solution where the model is just one component in a larger cognitive workflow.
Evaluation: The Antidote to Pilot Purgatory
Why do 88% of AI projects fail to scale? The most common culprit is a lack of rigorous evaluation (evals).
In the early days of a prototype, "vibes" are sufficient. A developer asks a few questions, reads the answers, and decides the bot is "good enough." But vibes do not scale. You cannot vibe-check 10,000 customer interactions a day. Without concrete metrics, executives cannot justify the risk of deployment, and the project dies in the pilot phase.
Building an eval suite is arguably harder than building the application itself. It requires:
- Golden Datasets: A curated list of inputs and "correct" outputs (which can be subjective).
- Model-Based Evaluation: Using a stronger model (e.g., GPT-4) to grade the outputs of a faster, cheaper model.
- Unit Testing for Intelligence: Breaking down a complex task (like writing a report) into sub-steps (search, summarize, synthesize) and evaluating each step independently.
Chip Huyen notes that while not every feature needs a complex eval, the core value proposition of the product does . If you are building a coding agent, you must have a way to measure if the code actually runs. If you are building a legal summarizer, you must measure factual accuracy. The companies that escape pilot purgatory are the ones that treat evals as a first-class citizen of the development lifecycle.
The Rise of the AI Engineer
We are witnessing the birth of a new engineering discipline. The AI Engineer is distinct from the traditional Machine Learning Engineer.
- ML Engineers build models. They worry about loss curves, gradient descent, and GPU utilization.
- AI Engineers build with models. They worry about latency, context windows, prompt orchestration, and user experience.
This role requires a hybrid skillset. It demands the architectural rigor of a backend engineer (to manage the complex state of agents and RAG pipelines) combined with the product intuition of a designer (to understand how users interact with probabilistic software).
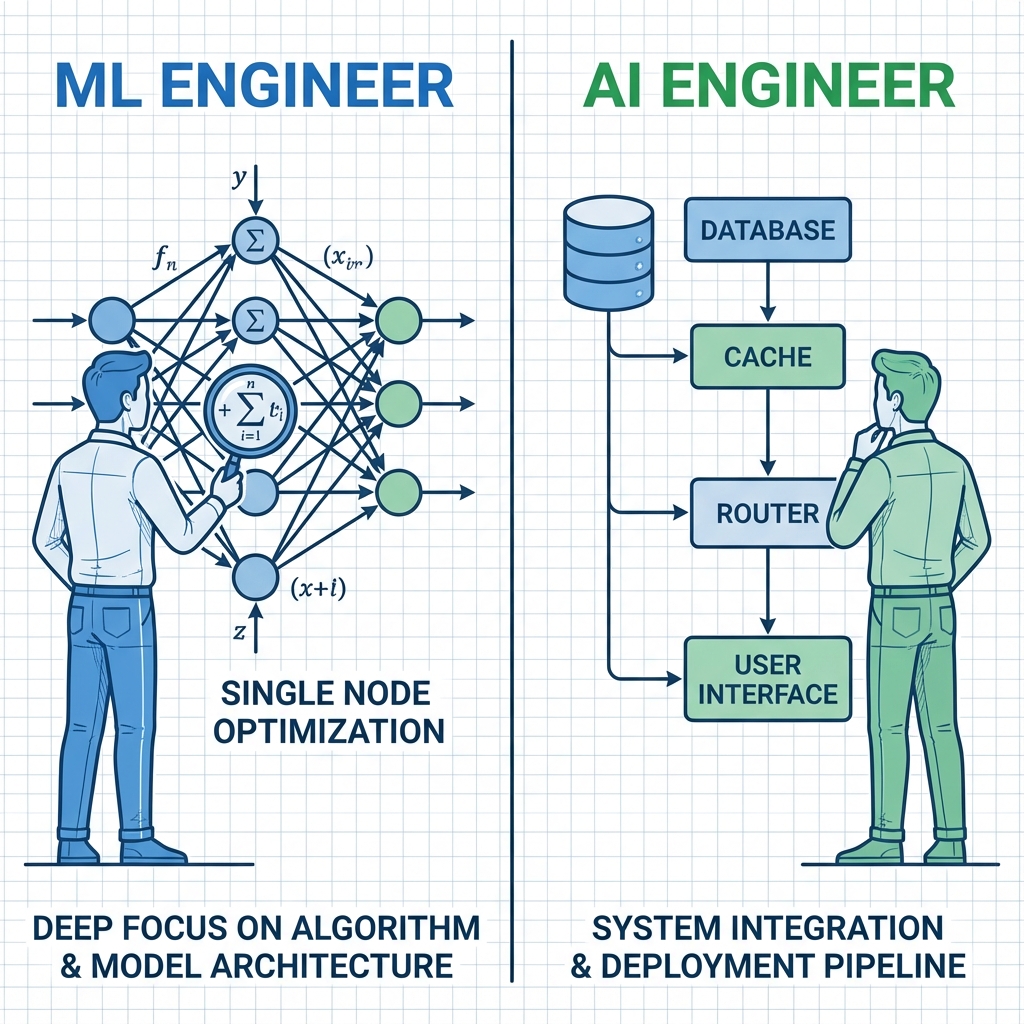
The Shift in Focus: The AI Engineer's role is not to build the brain, but to build the nervous system that connects the brain to the real world.
The future of software is not just about writing code; it is about orchestrating intelligence. As models plateau or become commoditized, the value accrues to those who can weave them into reliable, useful systems. The "Idea Crisis" will not be solved by a smarter GPT-5. It will be solved by engineers who stop waiting for magic and start building the scaffolding required to make the magic useful.
I take on a small number of AI insights projects (think product or market research) each quarter. If you are working on something meaningful, lets talk. Subscribe or comment if this added value.
Appendices
Glossary
- Test-Time Compute: The practice of allocating more computational resources during the inference phase (when the model is generating an answer) to allow for 'reasoning loops,' self-correction, and chain-of-thought processing.
- RAG (Retrieval Augmented Generation): A technique where an AI model is provided with external data (retrieved from a database) to answer questions, reducing hallucinations and enabling access to private or up-to-date information.
- RLHF (Reinforcement Learning from Human Feedback): A post-training method where human ratings of model outputs are used to train a 'reward model,' which then guides the AI to produce more desirable responses.
- Pilot Purgatory: A common state in enterprise AI where a project succeeds as a small-scale proof of concept (pilot) but fails to scale into a production-ready application due to cost, reliability, or organizational issues.
Contrarian Views
- Some experts argue that 'Test-Time Compute' is a temporary patch and that pre-training scaling laws (making models bigger) will eventually render complex inference engineering obsolete.
- The 'Idea Crisis' might not be a lack of ideas, but a lack of feasible ideas given current model limitations (e.g., reliability and hallucination rates are still too high for many critical business functions).
Limitations
- The article focuses heavily on text-based LLMs and does not deeply explore the specific engineering challenges of computer vision or robotics.
- The distinction between ML Engineers and AI Engineers is still fluid; in many startups, one person performs both roles.
Further Reading
- AI Engineering: Building Applications with Foundation Models - https://www.oreilly.com/library/view/ai-engineering/9781098166298/
- OpenAI's o1 and Inference-Time Scaling - https://www.tanayj.com/p/openais-o-1-and-inference-time-scaling
References
- Chip Huyen on Building AI Products - Lenny's Podcast (video, 2024-05-20) https://www.youtube.com/watch?v=example-video-url -> Primary source for concepts on AI engineering, RAG data prep, and the 'idea crisis'.
- OpenAI's o1 and inference-time scaling laws - Tanay's Newsletter (news, 2024-10-28) https://www.tanayj.com/p/openais-o-1-and-inference-time-scaling -> Explains the concept of test-time compute and the shift from pre-training scaling to inference scaling.
- Why 88% of AI Projects Fail (And It's Not the Technology) - DataDrivenInvestor (news, 2025-10-21) https://medium.com/datadriveninvestor/why-88-of-ai-projects-fail-and-its-not-the-technology-70b198019801 -> Provides statistical evidence for the 'pilot purgatory' phenomenon and high failure rates of AI projects.
- AI Engineering: Building Applications with Foundation Models - O'Reilly Media (book, 2024-01-01) https://www.oreilly.com/library/view/ai-engineering/9781098166298/ -> Foundational text defining the role of the AI Engineer vs ML Engineer.
Recommended Resources
- Signal and Intent: A publication that decodes the timeless human intent behind today's technological signal.
- Thesis Strategies: Strategic research excellence — delivering consulting-grade qualitative synthesis for M&A and due diligence at AI speed.
- Blue Lens Research: AI-powered patient research platform for healthcare, ensuring compliance and deep, actionable insights.
- Lean Signal: Customer insights at startup speed — validating product-market fit with rapid, AI-powered qualitative research.
- Qualz.ai: Transforming qualitative research with an AI co-pilot designed to streamline data collection and analysis.